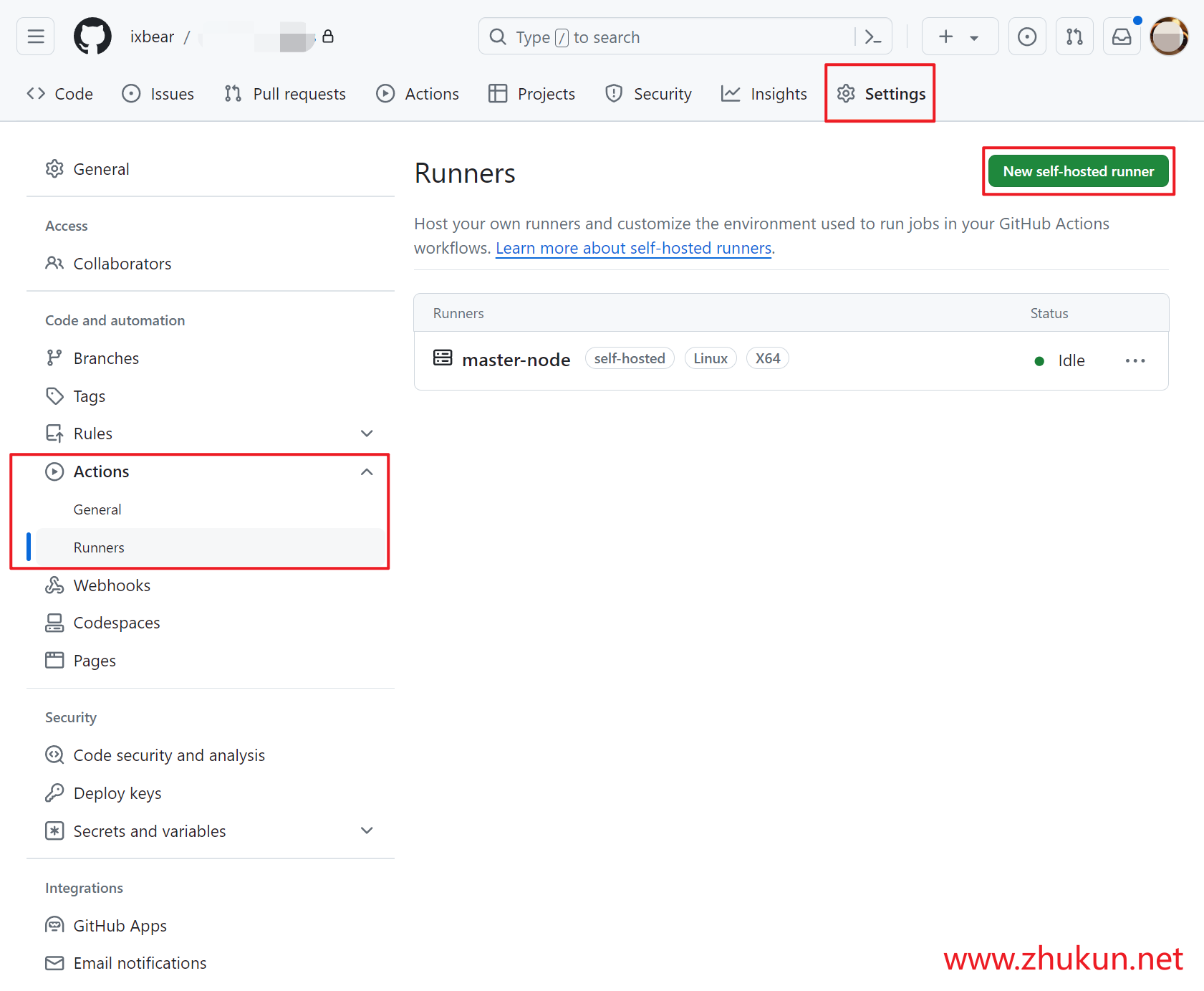
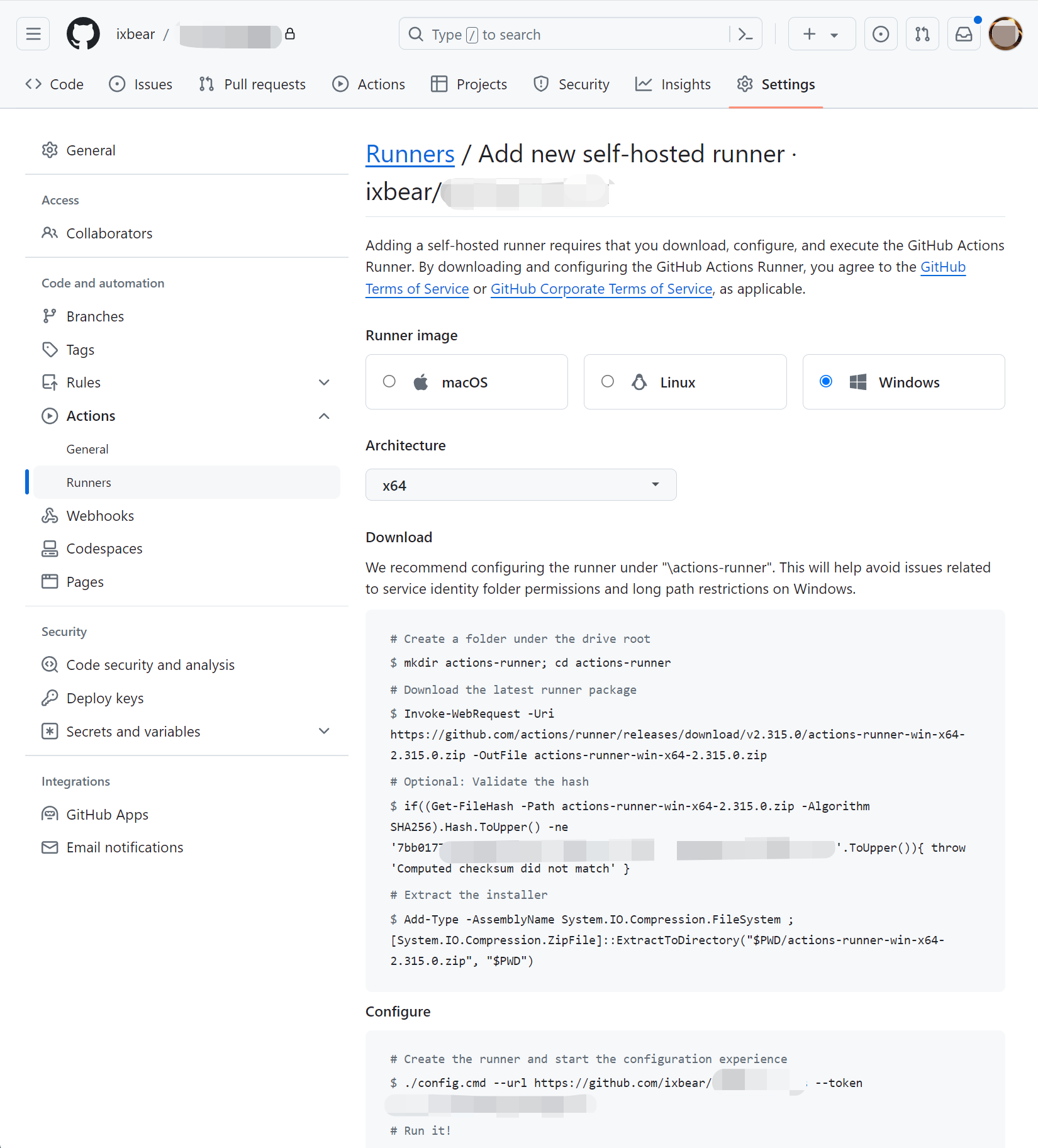
回国见闻
出国整整3.5年, 真的是豪无意外的生疏了国内的各种规则.
五一黄金周
五一假期的每一天都不适合出游, 注意是每一天, 甚至是最后一天.
我是5月4号抵达香港的, 当时以为是最后2天了, 人应该没有那么多了. 结果证明是自己 too young too naive 了. 那天跑了4家银行, 很多银行门口都是各种办港卡的人, 他们繁忙的在手机上点来点去. 去问银行柜台, 要么被告知今天名额满了, 要么只能办100W资产以上的银行卡.
工银亚洲门口的保安老大爷提示我们可以去某处“远程见证开户”. 于是我风尘仆仆的跑到第一个远程开户点, 发现只有1台机器可以”远程见证开户”, 且人已经排队到网点大门外了. 排了半小时队, 里面终于有1位同胞完成了见证开户出来了. 同胞说, 进去以后系统排队至少还要1小时起, 即使排上了, 办卡业务也得持续1小时起. 于是放弃, 坐港铁来到了第2个可以远程见证开户的点, 幸运的是这里居然没有人排队, 而且有2台机器可以”见证开户”, 于是排队了1小时以后, 终于有了1台空机器, 我进去又排了半小时, 机器终于接通了远程客服. 一顿提交资料, 期间甚至提交了加拿大银行超过百万人民币等值资产的证明. 结果, 竟然被客服告知开户申请被拒了. 此时又过去了整整1个小时.
这天, 抽空下载了汇丰, 中银的App, 尝试在App上申请开户. 汇丰提交成功了, 说是几个工作日以后给出结果. 中银App甚至没有走到最后一步系统就直接提示不满足开户要求. 我TM.
回去的路上, 我暗暗告诉自己, 以后再也不会去办工银亚洲和中银的卡.
人际沟通
很多年前, 跟朋友约饭的时候, 我都会说一句”避开牛蛙和海鲜, 其它我都可以”. 然后吃饭一直都比较开心的. 出国几年以后, 我忘记了这一点.
那晚抵达广州, 朋友擅作主张的选了一家火到不行的必吃榜餐厅, 一去的时候门口就坐满了各种排队的人, 可想而知它家的火爆. 但当真正点餐的时候, 我傻眼了, 它家榜上有名的菜几乎全是海鲜.
结果可想而知, 我尴尬了吃了几只炸虾, 就借口吃饱了. 那晚明明没吃饱, 却只能饿着肚子去朋友家. 路上看到各种小笼包, 各种大排档, 口水都快流出来了.
人口素质
这一点, 真的是国内国外一个样了. 我在香港机场转机的时候, 看到不远处有一个空的坐椅, 于是走过去准备坐下. 但就当我距离那个坐位仅剩2米且低头看了一下手机的时候, 一个大姐以超光速冲到那里并坐了下去. 然后大姐立即用手指的方式告诉不远处的朋友那里还有一个空位置. 当时很无语, 也知道这大姐豪无疑问的是中国人. 因为早有心理预期, 心里上也告诉自己别为了这种事情生气.
随后回到了国内, 也辗转了好几个地方, 发现国内有素质的人还是很多, 甚至是一点也不比国外少.
Read More