假设有一天,你有一个任务,要统计线上所有服务器的/export分区占用情况,比如下面这一台服务器:
$ df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda1 ext4 20G 5.2G 13G 29% /
tmpfs tmpfs 127G 0 127G 0% /dev/shm
/dev/sda3 ext4 514G 279G 209G 58% /export
/dev/sdb1 ext4 1.1T 518G 526G 50% /export/Data/jd_search
像这样一台服务器,除了有个/export分区,还有个/export/Data/jd_search(只有一部分机器有这个分区),现在要统计这2个分区的占用情况,并且最终形成Excel报表,要怎么操作呢?
1,使用批量脚本获得所有机器的/export分区占用情况
#准备远程机器列表
$ vim ip_list
10.191.172.201
10.190.143.38
10.187.110.4
10.190.49.237
10.190.198.192
10.190.163.211
使用ansible将本机的(admin用户的)key推送到所有机器上(的admin用户),实现从本机免密码登陆到所有机器
$ vim deploy_ssh_key.yml #准备push ssh-key
- hosts: all
remote_user: admin
gather_facts: no
tasks:
- name: install ssh key
authorized_key: user=admin
key="{{ lookup('file', '/home/admin/.ssh/id_rsa.pub') }}"
state=present
开始批量推送ssh_key
$ ansible-playbook -i ip_list deploy_ssh_key.yml -k #推送ssh key, 需要输入密码
使用批量执行的脚本
$ vim cmd.sh
#!/bin/bash
ip_list_file=$1
IP_LIST=`cat $ip_list_file`
for dst_ip in ${IP_LIST[@]}; do
echo -e "$dst_ip \c"
ssh ${dst_ip} "df -hT | grep /export | egrep -v bigtable"
done
运行批量执行的脚本,获得所有机器的/export分区占用情况
$ sh cmd.sh ip_list
172.28.35.21 /dev/sda5 ext4 1.1T 590G 418G 59% /export
172.28.35.32 /dev/sda5 ext4 1.1T 590G 417G 59% /export
172.28.139.13 /dev/sda3 ext4 515G 79G 411G 17% /export
/dev/sdb ext4 1.1T 522G 524G 50% /export/Data/jd_search
172.28.139.14 /dev/sda3 ext4 515G 107G 383G 22% /export
/dev/sdb ext4 1.1T 523G 522G 51% /export/Data/jd_search
172.28.139.24 /dev/sda3 ext4 515G 74G 415G 16% /export
172.28.139.35 /dev/sda3 ext4 789G 403G 347G 54% /export
172.28.139.55 /dev/sda3 ext4 514G 91G 398G 19% /export
/dev/sdb ext4 1.1T 522G 523G 50% /export/Data/jd_search
172.28.148.55 /dev/sda5 ext4 513G 72G 416G 15% /export
/dev/sdb ext4 1.1T 522G 520G 51% /export/Data/jd_search
172.28.35.12 /dev/sda5 ext4 1.1T 591G 417G 59% /export
172.28.35.22 /dev/sda5 ext4 1.1T 591G 417G 59% /export
172.28.35.33 /dev/sda5 ext4 1.1T 592G 416G 59% /export
2,生成Excel报表
按常归方式形成Excel报表
$ sh cmd.sh ip_list | awk 'BEGIN {OFS=",";} {print $1,$2,$3,$4,$5,$6,$7,$8}' > result.csv
awk输出的时候,指定逗号为分隔符,用来形成报表
打开报表看看,总感觉有哪里不对,有些列好像没有对上
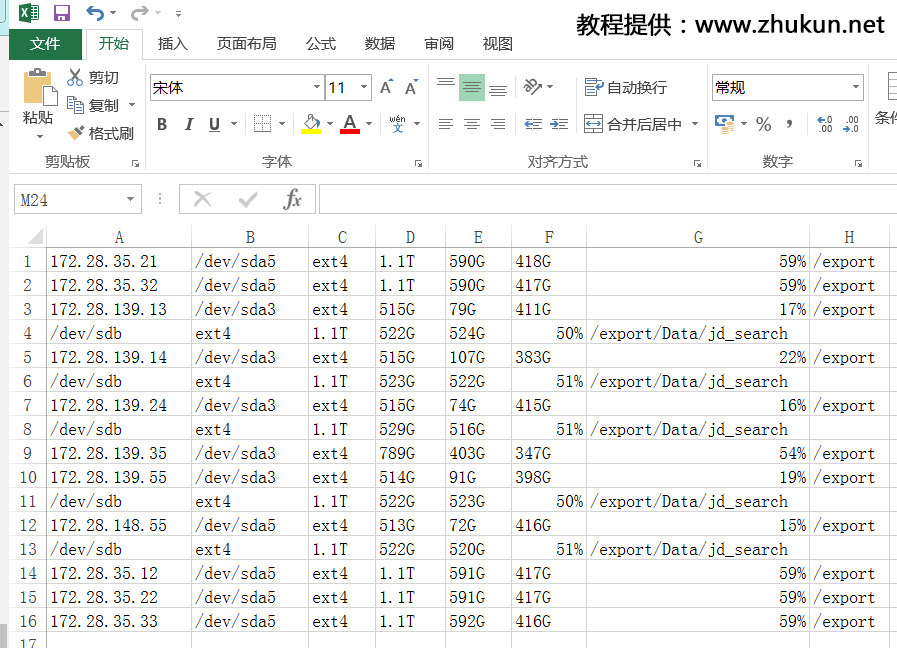
重新生成报表
$ sh cmd.sh ip_list | awk 'BEGIN {OFS=",";} {if (NF==8){print $1,$2,$3,$4,$5,$6,$7,$8} else if(NF==7){print "",$1,$2,$3,$4,$5,$6,$7}}' > result2.csv
awk输出的时候,指定逗号为分隔符,如果一行有8个参数(空格为分隔符),则输出8个参数,如果一行只有7个参数,则将第一个参数设置为空,后面输出7个参数
这回再看,就没有问题了
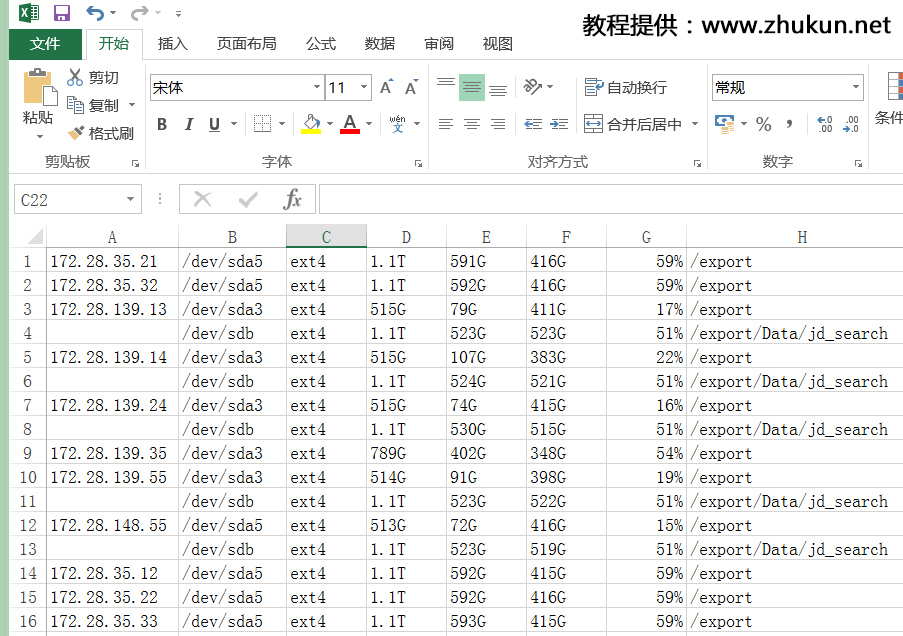
3,在命令行中生成简单报表(2017.09.07补充)
使用批量执行的脚本
$ vim cmd.sh
#!/bin/bash
ip_list_file=$1
IP_LIST=`cat $ip_list_file`
for dst_ip in ${IP_LIST[@]}; do
echo -e "$dst_ip \c"
ssh ${dst_ip} "df -hT | grep /export | egrep -v '(bigtable)' | awk 'END{ if(NR=1) print \$5, \$7; else if(NR=2 && \$7=="/export/Data/jd_search") print \$5, \$7}'"
done
这里进行了一下筛选,如果有/export/Data/jd_search分区,则返回这个分区的剩余空间,否则就返回/export分区的剩余空间。针对awk的详细解释请看这篇文章《awk命令之条件判断》
执行结果
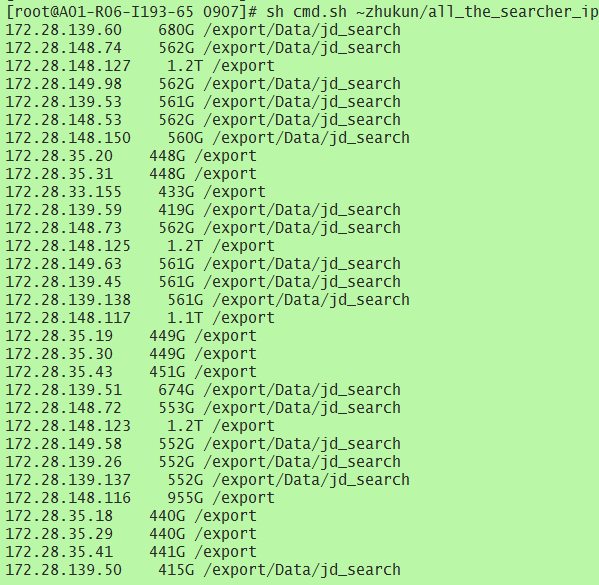
Leave a Reply