配置ELK系统(ElasticSearch+Logstash+Kibana)收集nginx系统日志(一)
环境设定
192.168.33.10 #安装ElasticSearch及kibana, 建议内存4G以上
192.168.33.11 #安装logstash, 建议内存4G以上
192.168.33.12 #安装filebeat及nginx, 建议内存2G以上
原理分析
1, ELK系统随着逐渐完善, 出现了一些其它的组件, 例如beats. filebeat作为beats家族的一员, 用来收集nginx的日志, 并将其发送给logstash, 因此filebeat需要指定nginx日志的位置及logstash的地址/端口信息.
2, logstash收到日志以后, 对日志进行解析(filter, 分析出其中的关键片断, 例如时间/客户端IP/访问URL/HTTP返回状态等信息), 然后传送给ElasticSearch.
3, kibana负责展示ElasticSearch里的日志内容
准备工作
以下操作需要在所有节点上进行.
如果是CentOS/Redhat系统, 请关闭selinux
$ getenforce #如果返回Enforcing则执行下面2条语句
$ setenforce 0
$ sed -i '/^SELINUX=/cSELINUX=disabled' /etc/sysconfig/selinux
# 安装jdk 1.8
$ sudo yum install -y java-1.8.0-openjdk-headless #适用于CentOS 7/Redhat 7
$ sudo apt update && sudo apt install openjdk-8-jre #适用于Ubuntu/Debian配置好APT/RPM repository(然后就可以使用rpm install/ apt insall的方式来安装了. 本文强列推荐APT/RPM repository的安装方式, 使用因为安装了ElasticSearch之后, 还需要安装filebeat等相关组件)
Ubuntu系统参考这篇文章配置APT repository
CentOS系统参考这篇文章配置RPM repository
下面开始正式安装过程.
1, 安装ElasticSearch及kibana
本文中的ElasticSearch及kibana安装在192.168.33.10上面.
$ yum install elasticsearch kibana #适用于CentOS/Redhat
$ sudo apt install elasticsearch kibana #适用于Ubuntu/DebianElasticSearch主要配置文件
/etc/elasticsearch/elasticsearch.yml #用于配置集群节点信息
/etc/elasticsearch/jvm.options
/etc/elasticsearch/log4j2.properties
/etc/sysconfig/elasticsearch #配置服务相关信息, 例如JAVA_HOME路径等配置ElasticSearch
$ cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.`date +%Y%m%d`
$ vim /etc/elasticsearch/elasticsearch.yml #修改如下配置
cluster.name: my_es #集群的名字, 所有节点应该一样, 否则会出错
node.name: node1 #(集群中的)该节点名字, 建议与本机hostname一致
network.host: 192.168.33.10 #监听IP
http.enabled: true
http.port: 9200 #es服务的端口号
transport.tcp.port: 9300
transport.tcp.compress: true
http.max_content_length: 100mb
#如果是ElasticSearch集群, 还需要设定以下3项
node.master: true #该节点有资格成为master node
node.data: true #该节点是数据节点
discovery.zen.ping.unicast.hosts: [192.168.33.10, 192.168.33.110, 192.168.33.120] #写入其它ES集群node信息
discovery.zen.minimum_master_nodes: 2 # 这个非常重要,务必根据实际情况修改
gateway.recover_after_nodes: 4特别注意:
1, node.master: true并不是表示它是master node, 而是有资格被推举成为master node;
2, discovery.zen.minimum_master_nodes设置为2, 表示集群中有2个具备主节点资格的node在线时, 才会推举其中之一作为master node. 建议设定的值为(主节点数量/2 + 1), 例子: 当集群中有7个具备master node资格的节点时, 可能会出现其中3台推举了一个主节点, 另外4台又推举了一个主节点. 所以此值应该设定为4, 就不会出现这样的情况, 即至少4台master node在线才能推举主节点.
如果你希望展示出来图形化的地理位置信息和浏览器信息, 那么需要安装以下2个插件(参考这里), 安装完插件以后需要重启Elasticsearch:
$ /usr/share/elasticsearch/bin/elasticsearch-plugin install ingest-geoip
$ /usr/share/elasticsearch/bin/elasticsearch-plugin install ingest-user-agent启动ElasticSearch服务(速度会较慢,可能需要1分钟才启动)
$ systemctl enable elasticsearch.service
$ systemctl restart elasticsearch.service
$ systemctl status elasticsearch.service
# 确保ElasticSearch服务启动成功
$ netstat -antp | egrep '(9200|9300)' #如果发现只有9200启动,不用着急,es服务启动比较慢
tcp6 0 0 192.168.33.10:9200 :::* LISTEN 3814/java
tcp6 0 0 192.168.33.10:9300 :::* LISTEN 3814/java
# 查看节点信息
$ curl 'http://127.0.0.1:9200'
{
name : master.node,
cluster_name : my-es,
cluster_uuid : -P9IQ2y_TwOG3Kh1Pzfq3g,
version : {
number : 6.4.2,
build_flavor : default,
build_type : deb,
build_hash : 04711c2,
build_date : 2018-09-26T13:34:09.098244Z,
build_snapshot : false,
lucene_version : 7.4.0,
minimum_wire_compatibility_version : 5.6.0,
minimum_index_compatibility_version : 5.0.0
},
tagline : You Know, for Search
}
$ curl 'http://192.168.33.10:9200/_cluster/health?pretty'
{
cluster_name : my-es,
status : yellow,
timed_out : false,
number_of_nodes : 1,
number_of_data_nodes : 1,
active_primary_shards : 6,
active_shards : 6,
relocating_shards : 0,
initializing_shards : 0,
unassigned_shards : 5,
delayed_unassigned_shards : 0,
number_of_pending_tasks : 0,
number_of_in_flight_fetch : 0,
task_max_waiting_in_queue_millis : 0,
active_shards_percent_as_number : 54.54545454545454
}
$ curl 'http://192.168.33.10:9200/_cat/master'
W81289-4RteTUjDjLiM_aQ 192.168.33.10 192.168.33.10 master.node
$ curl 'http://192.168.33.10:9200/_cat/nodes' #因为本例只有一个node, 所以只会列出唯一的master节点
192.168.33.10 30 87 4 0.03 0.05 0.01 mdi * master.node如果启动失败, 排查以下日志文件
$ tail -20 /var/log/messages
$ tail -20 /var/log/elasticsearch/my-es.log配置kibana
$ cp /etc/kibana/kibana.yml /etc/kibana/kibana.yml.`date +%Y%m%d`
$ vim /etc/kibana/kibana.yml #增加或修改以下内容
server.port: 5601 # kibana监听端口
server.host: 192.168.33.10 # kibana监听ip
elasticsearch.url: http://192.168.33.10:9200 # 配置es服务器的ip, 如果是集群则配置该集群中主节点的ip
logging.dest: /var/log/kibana.log # 配置kibana的日志文件路径, 否则日志会默认写入messages文件
# 建立kibana日志文件
$ touch /var/log/kibana.log; chmod 777 /var/log/kibana.log启动Kibana服务
$ systemctl enable kibana.service
$ systemctl restart kibana.service
$ systemctl status kibana.service
# 确认Kibana启动成功(可能需要10s的时间来启动)
$ netstat -antp | grep :5601
tcp 0 0 192.168.33.10:5601 0.0.0.0:* LISTEN 5338/node提示: 由于kibana是使用node.js开发的, 所以进程名称为node.
然后在浏览器里进行访问http://192.168.33.10:5601/, 由于我们并没有安装x-pack, 所以此时是没有用户名和密码的, 可以直接访问的.
2, 安装配置filebeat
在安装了nginx的server上安装配置filebeat, 本例是192.168.33.12, 因此需要在这一台上安装nginx及filebeat.
$ yum install epel-release #需要先安装epel源, 才能安装nginx
$ yum install nginx
$ systemctl restart nginx
$ curl http://192.168.33.12 #确保nginx可被访问
$ yum install filebeat
$ cp /etc/filebeat/filebeat.yml /etc/filebeat/filebeat.yml.`date +%Y%m%d`
$ vim /etc/filebeat/filebeat.yml #修改或添加以下内容
filebeat.inputs:
- type: log
enabled: true
paths:
#- /var/log/messages #注释掉系统日志
/var/log/nginx/*.log #添加nginx日志
exclude_files: ['.gz$']
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
#setup.kibana: #取消向kibana输出
#host: localhost:5601
#output.elasticsearch: #取消向elasticsearch输出
# Array of hosts to connect to.
#hosts: [localhost:9200]
output.logstash: #开启向logstash输出
hosts: [192.168.33.11:5400]启动filebeat服务
$ systemctl enable filebeat
$ systemctl restart filebeat
#确认服务启动成功
$ ps -ef | grep filebeat
root 8848 1 1 03:30 ? 00:00:02 /usr/share/filebeat/bin/filebeat -c /etc/filebeat/filebeat.yml -path.home...如果启动失败, 排查以下日志文件
$ tail -20 /var/log/messages
$ tail -20 /var/log/filebeat/filebeat3, 安装及配置logstash
本文中的Logstash安装在192.168.33.11上面.
$ yum install logstash
$ cp /etc/logstash/logstash.yml /etc/logstash/logstash.yml.`date +%Y%m%d`
$ vim /etc/logstash/logstash.yml #修改如下配置项
...
path.data: /var/lib/logstash
path.config: /etc/logstash/conf.d
...
http.host: 192.168.33.11
path.logs: /var/log/logstash
...写入nginx日志的解析规则
$ vim /etc/logstash/conf.d/logstash-nginx-es.conf #写入如下内容
input {
beats {
host => 0.0.0.0
port => 5044
}
}
filter {
grok {
match => { message => %{IPORHOST:remote_ip} - %{DATA:user_name} \[%{HTTPDATE:access_time}\] \%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\ %{NUMBER:response_code} %{NUMBER:body_sent_bytes} \%{DATA:referrer}\ \%{DATA:agent}\ }
remove_field => message
}
}
output {
elasticsearch {
hosts => [192.168.33.10:9200]
index => weblogs_index_pattern-%{+YYYY.MM.dd} #这个weblogs_index_pattern就是kibana里面的index_pattern,可以改成自定义的名字
}
stdout { codec => rubydebug }
}知识点解析:
1, stdout { codec => rubydebug }这一段, 是用来测试标准输出的(测试完可以删除这一段). 加上这一段以后, 会把解析到的字段信息打印到console上, 如果是systemd方式启动的服务, 会把打印到的内容打印到/var/log/messages中.
2, remove_field => “message”这一段, 表示把整条日志字段删除, 因为在上面已经通过match方法获得了remote_ip/access_time/http_method/http_version/response_code等字段信息, 整条日志已经没有意义了, 因此这里可以remove之.
3, 通过这个conf文件, 我们可以留意到logstash配置文件的语法为:
input {
# 这里配置logstash的监听地址及端口, 以便filebeat可以向这里地址发送日志
}
filter {
# 接收到nginx的日志以后, 这里指定如何解析nginx日志
}
output {
# 解析以后的nginx发往何处, 一般是发送到ElasticSearch服务器
}4, 这是的grok仅仅写了nginx的access.log的匹配规则, 但是nginx除了access.log, 还有一个error.log, 我们这里并未作匹配.因此, 如果Filebeat抓取到了error.log, 这里是无法做出解析的. 解决方案为: 在Filebeat启用nginx模块以后, 在grok里判断日志是access.log还是error.log, 除了nginx以外, 官网的这篇文章还提供了Apache, Mysql的日志匹配写法.
在启动logstash之前, 我们需要先测试logstash的配置文件是否正常工作.
#测试配置文件(可能需要数分钟才会返回结果)
$ cd /etc/logstash
$ /usr/share/logstash/bin/logstash --path.settings ./ -f ./conf.d/logstash-nginx-es.conf --config.test_and_exit
#返回Configuration OK表示正常接下来我们进行第2个测试, 测试logstash能否正确抓取及解析nginx的日志. 我们这里开启2个logstash server(192.168.33.11)的终端, 一个不断访问nginx(192.168.33.12), 另一个测试日志抓取
#第一个终端
$ while true; do n=$(( RANDOM % 10 )); [ $n -gt 6 ] && { curl 192.168.33.12/err_page; } || curl 192.168.33.12/?$n; sleep $n; done
#第二个终端测试解析日志
$ cd /etc/logstash
$ /usr/share/logstash/bin/logstash -f ./conf.d/logstash-nginx-es.conf #返回如下信息就表示logstash可以正常解析nginx日志
{
response_code => 404,
source => /var/log/nginx/access.log,
body_sent_bytes => 3650,
message => 127.0.0.1 - - [29/Aug/2018:01:08:01 +0000] \GET /server-status?auto= HTTP/1.1\ 404 3650 \-\ \Go-http-client/1.1\ \-\,
http_version => 1.1,
http_method => GET,
@timestamp => 2018-08-29T01:08:03.712Z,
host => {
name => data2.node
},
offset => 3431209,
access_time => 29/Aug/2018:01:08:01 +0000,
agent => Go-http-client/1.1,
referrer => -,
url => /server-status?auto=,
beat => {
version => 6.4.0,
name => data2.node,
hostname => data2.node
},
prospector => {
type => log
},
input => {
type => log
},
user_name => -,
remote_ip => 127.0.0.1,
tags => [
[0] beats_input_codec_plain_applied
],
@version => 1
}
{
response_code => 200,
source => /var/log/nginx/access.log,
body_sent_bytes => 3700,
message => 192.168.33.11 - - [29/Aug/2018:01:08:02 +0000] \GET /?3 HTTP/1.1\ 200 3700 \-\ \curl/7.29.0\ \-\,
http_version => 1.1,
http_method => GET,
@timestamp => 2018-08-29T01:08:03.712Z,
host => {
name => data2.node
},
offset => 3431326,
access_time => 29/Aug/2018:01:08:02 +0000,
agent => curl/7.29.0,
referrer => -,
url => /?3,
beat => {
version => 6.4.0,
name => data2.node,
hostname => data2.node
},
prospector => {
type => log
},
input => {
type => log
},
user_name => -,
remote_ip => 192.168.33.11,
tags => [
[0] beats_input_codec_plain_applied
],
@version => 1
}测试没问题以后, 请把文件中stdout { codec => rubydebug }这一段删除. 因为不再需要用它来测试.
启动logstash
# 可能需要1-2分钟才会启动
$ systemctl enable logstash
$ systemctl restart logstash
# 确认启动成功(如果端口未监听不用担心,logstash启动时间较长,或者查看如下日志进行故障排查)
$ netstat -antp | egrep '(:9600|:5044)'
tcp6 0 0 127.0.0.1:9600 :::* LISTEN 7046/java
tcp6 0 0 :::5044 :::* LISTEN 7046/java
# 启动故障排查
$ tail -20 /var/log/messages
$ tail -20 /var/log/logstash/logstash-plain.log4, Kibana界面定制化分析
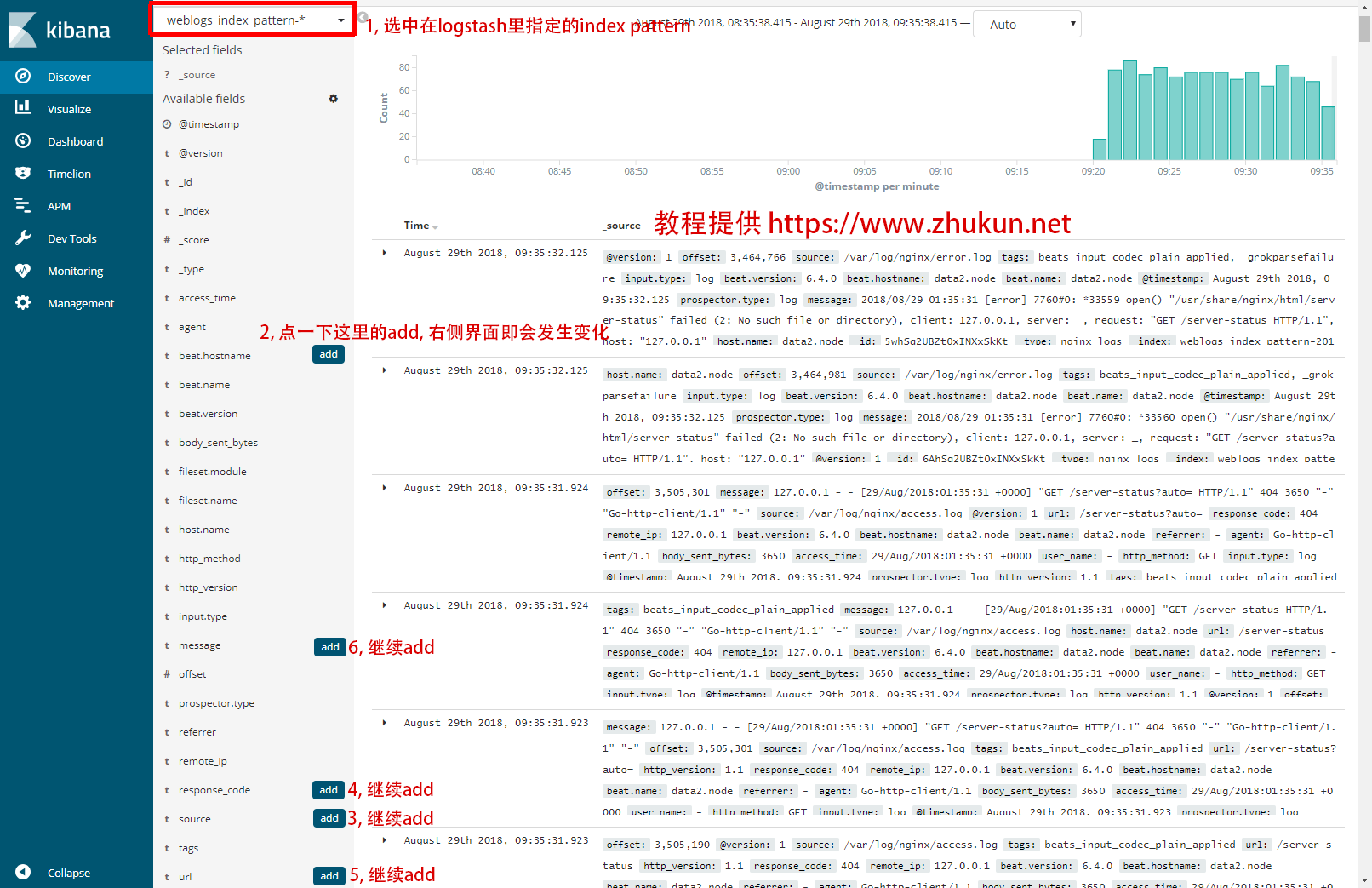
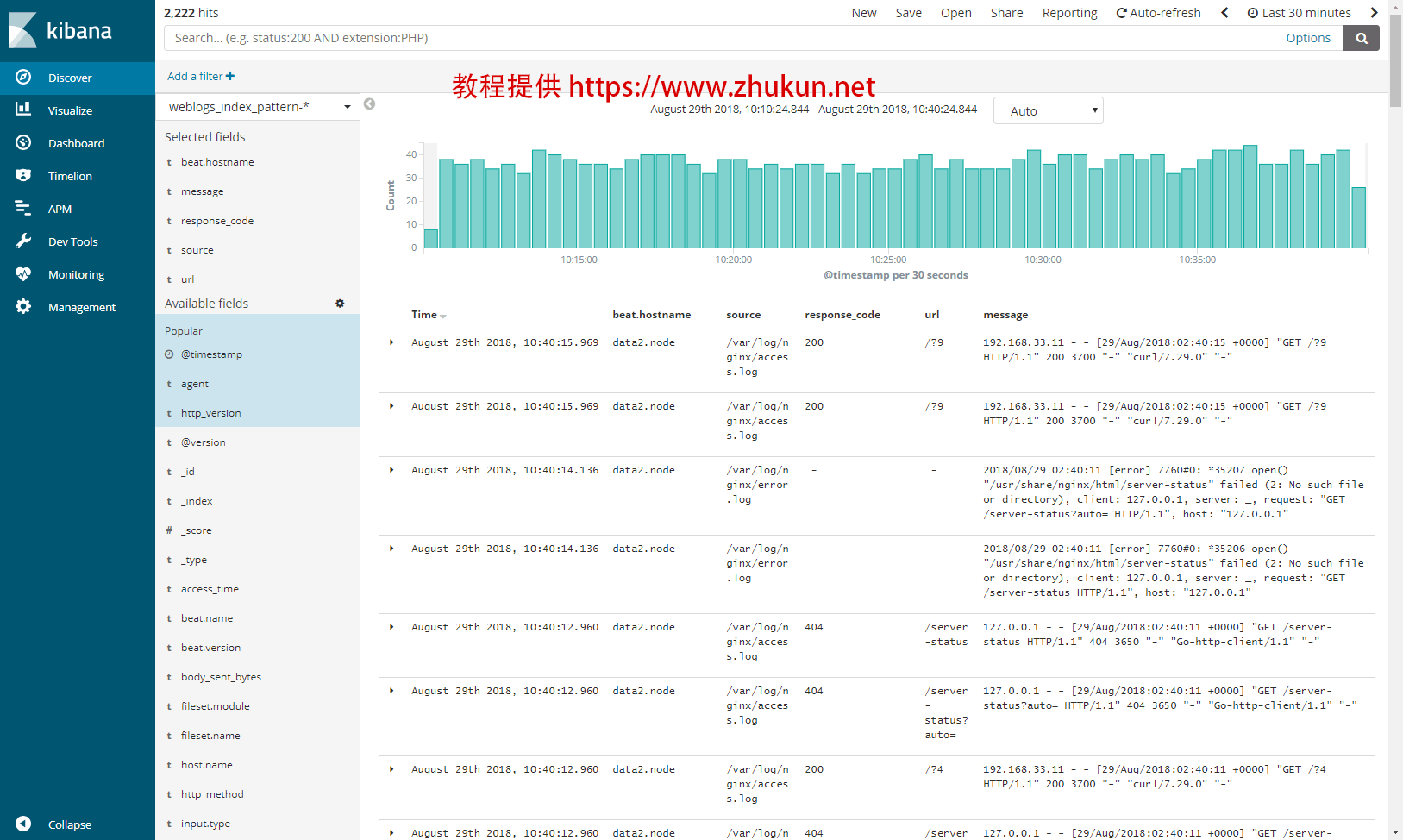
现在打开Kibana界面(本例中是http://192.168.33.10:5601), 点击左侧的”Discover”, 选择我们定义的index pattern.
乍一看上去, 数据好像比较混乱. 这里指导一下大家进行日志界面的定制化.
参考文档:
Transforming and sending Nginx log data to Elasticsearch using Filebeat and Logstash – Part 2