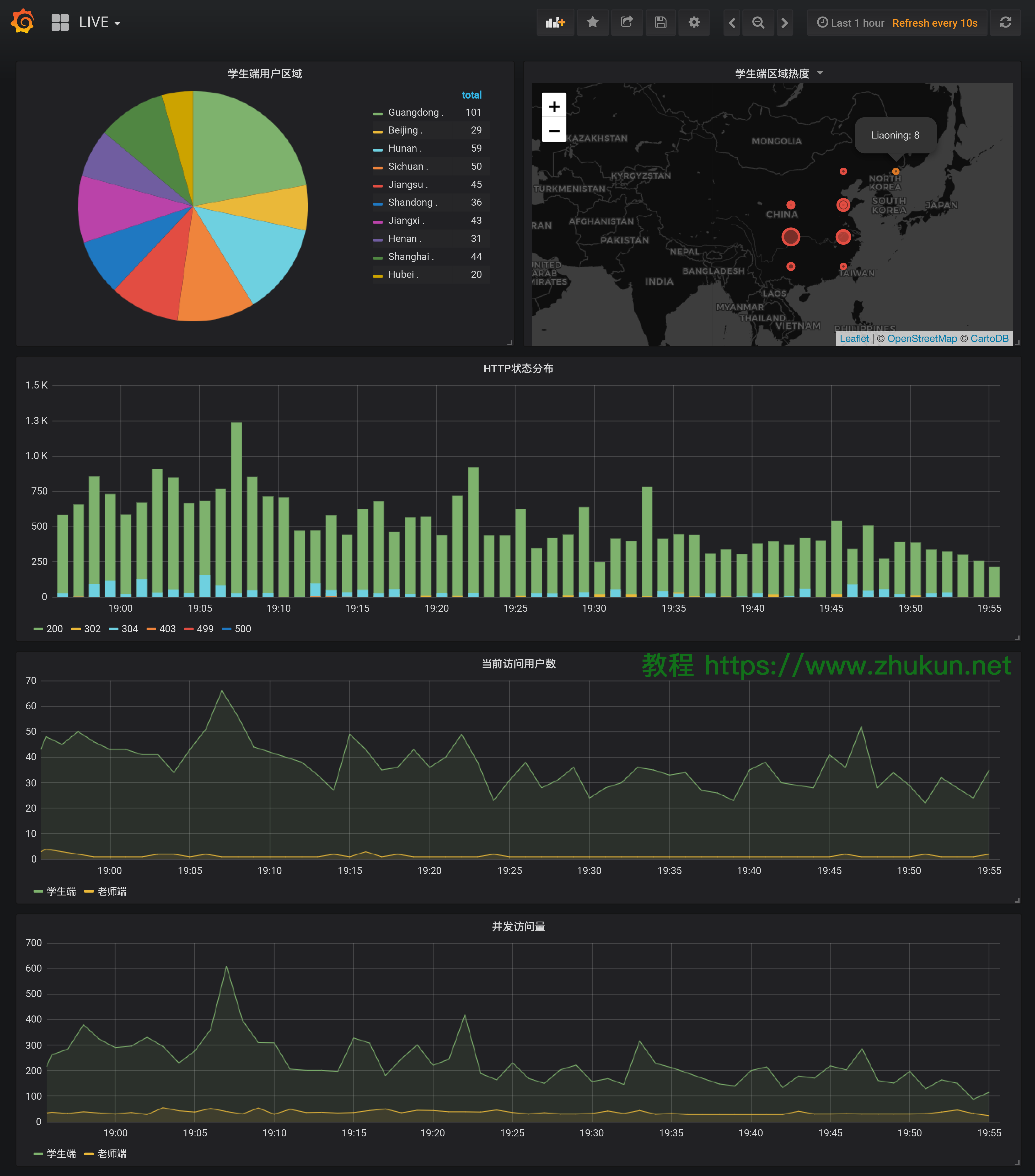
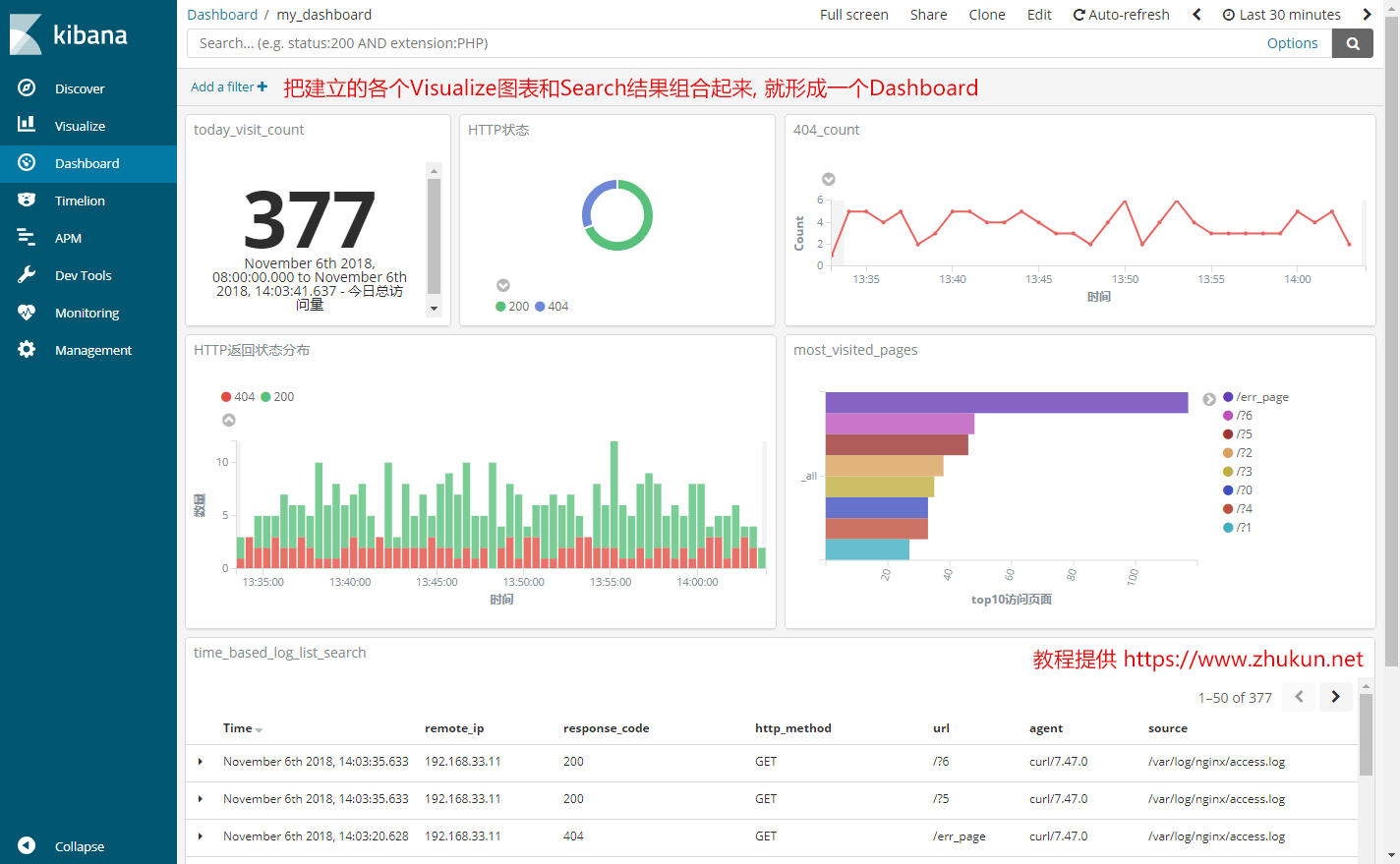
Prometheus中rate和irate的区别
rate()
rate(v range-vector) calculates the per-second average rate of increase of the time series in the range vector.
rate()函数计算某个时间序列范围内的每秒平均增长率。
Breaks in monotonicity (such as counter resets due to target restarts) are automatically adjusted for.
自适应单调性中断(比如target重启导致的计数器重置).
Also, the calculation extrapolates to the ends of the time range, allowing for missed scrapes or imperfect alignment of scrape cycles with the range’s time period.
计算结果是推算到每个时间范围的最后而得出, 允许漏抓和抓取周期与时间范围的不完美结合.
The following example expression returns the per-second rate of HTTP requests as measured over the last 5 minutes, per time series in the range vector:
以下示例返回最后五分钟HTTP请求每秒增长率
rate(http_requests_total{job="api-server"}[5m])
rate should only be used with counters. It is best suited for alerting, and for graphing of slow-moving counters.
rate应该只和计数器一起使用。最适合告警和缓慢计数器的绘图。 (more…)
Read More