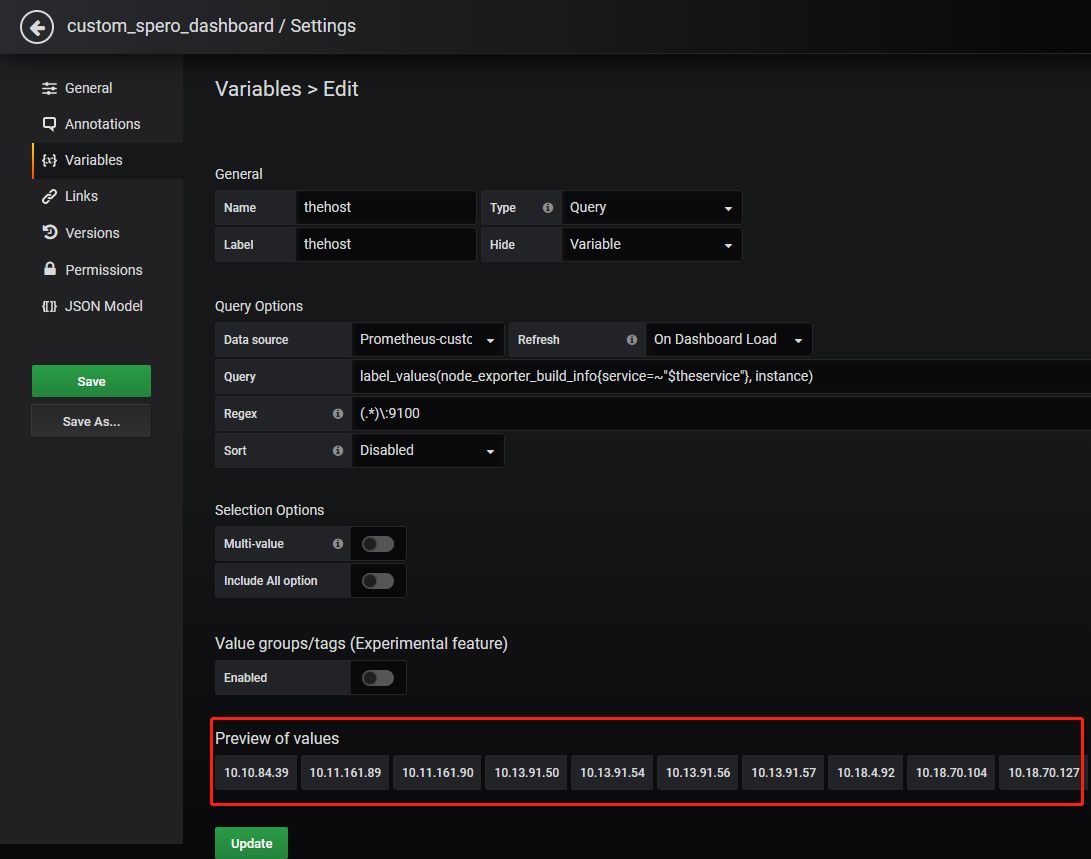
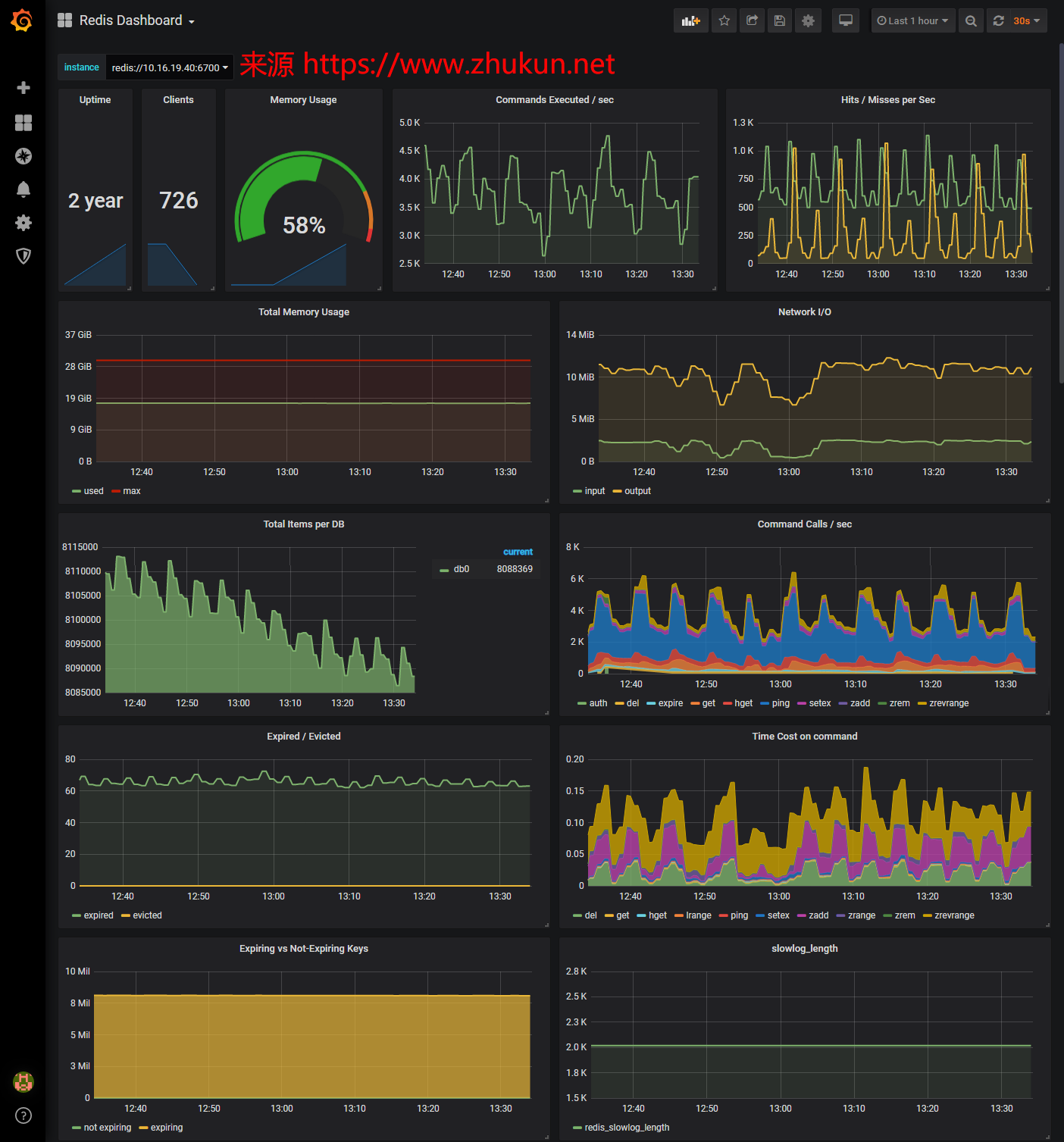
Redis监控(Grafana+Prometheus+redis_exporter)
先看一下最终的效果图(本文中的图片均可以点击查看大图)
环境准备
Promethus推荐的Exporter: https://prometheus.io/docs/instrumenting/exporters/
其推荐的是这个redis_exporter: https://github.com/oliver006/redis_exporter, 本文略过了Grafana+Prometheus+redis_exporter的安装过程, 我们假设redis_exporter的安装位置为/data/apps/redis_exporter/redis_exporter
查看每个机器上Redis的连接密码
$ grep requirepass /data/conf/redis/redis-670*.conf | grep -v '\#'
要监控的机器redis节点
此组redis密码:K8aBe56E 此组redis密码:uizJFaP9 10.16.19.37:6700 10.16.19.37:6703 10.16.19.37:6701 10.16.19.37:6704 10.16.19.37:6702 10.16.19.37:6705 10.16.19.40:6700 10.16.19.40:6703 10.16.19.40:6701 10.16.19.40:6704 10.16.19.40:6702 10.16.19.40:6705 10.16.19.58:6700 10.16.19.58:6703 10.16.19.58:6701 10.16.19.58:6704 10.16.19.58:6702 10.16.19.58:6705Read More