MacOS上设置”邮件”定时发送
在MacOS上想使用邮件定时发送的的功能可是太不容易了, 先后换过好几个客户端, Airmail的定时发送功能跟傻X一样, Outlook又卡成xiang, 找来找去找到了这个名为mailbulter的”邮件”插件(需要在MacOS原生邮件客户端设置里启用此插件).
查了下, mailbulter的免费套餐里有些功能只能使用30次/月(比如我需要的定时发送功能), 但是也够我用了, 先用着吧.
Read More不见去年人, 泪湿春衫袖。
在MacOS上想使用邮件定时发送的的功能可是太不容易了, 先后换过好几个客户端, Airmail的定时发送功能跟傻X一样, Outlook又卡成xiang, 找来找去找到了这个名为mailbulter的”邮件”插件(需要在MacOS原生邮件客户端设置里启用此插件).
查了下, mailbulter的免费套餐里有些功能只能使用30次/月(比如我需要的定时发送功能), 但是也够我用了, 先用着吧.
Read More迁移ElasticSearch集群的数据, 最好用的是用到ElasticSearch的CCR(Cross-cluster replication, 跨集群复制)功能(官方文档在此). 但无奈今天配置了一天, 怎么也没有成功. 其实CCR存在的意义不仅仅是迁移数据, 更重要的是保证ElasticSearch集群的多副本/高可用状态. 比如, 如果你的主ES集群不能对外暴露, 那么可以设置一个readonly的对外暴露集群(数据通过CCR功能与主集群保持同步, 等. 而如果仅仅是迁移数据的话, 只用到ES的reindex功能即可完成.
将旧集群(172.29.4.168:9200)里的mail-w3svc1-2020.06.06索引数据迁移过来, 仅需要在新集群上执行如下命令即可.
curl -X POST "localhost:9200/_reindex?pretty" -H 'Content-Type: application/json' -d'
{
"source": {
"remote": {
"host": "http://172.29.4.168:9200",
"username": "elastic",
"password": "MyPassword"
},
"index": "mail-w3svc1-2020.06.06"
},
"dest": {
"index": "mail-2020.06.06"
}
}'
参考文档:
Reindex API
这么常用的一个APP, APPLE中国商店居然不提供下载. 好吧, 总算让我找到一个最新版的下载地址.
直接下载地址: https://go.microsoft.com/fwlink/?linkid=868963
参考: Microsoft Remote Desktop now available outside the App Store
Read More先前写过一篇ElasticSearch对接Grafana展示Nginx日志数据, 以及kibana使用的lucene查询语法, 今天试着把2者中和一下. 做一个Dashboard.
先看一张整体图(本文中的图片均可以点击查看大图)
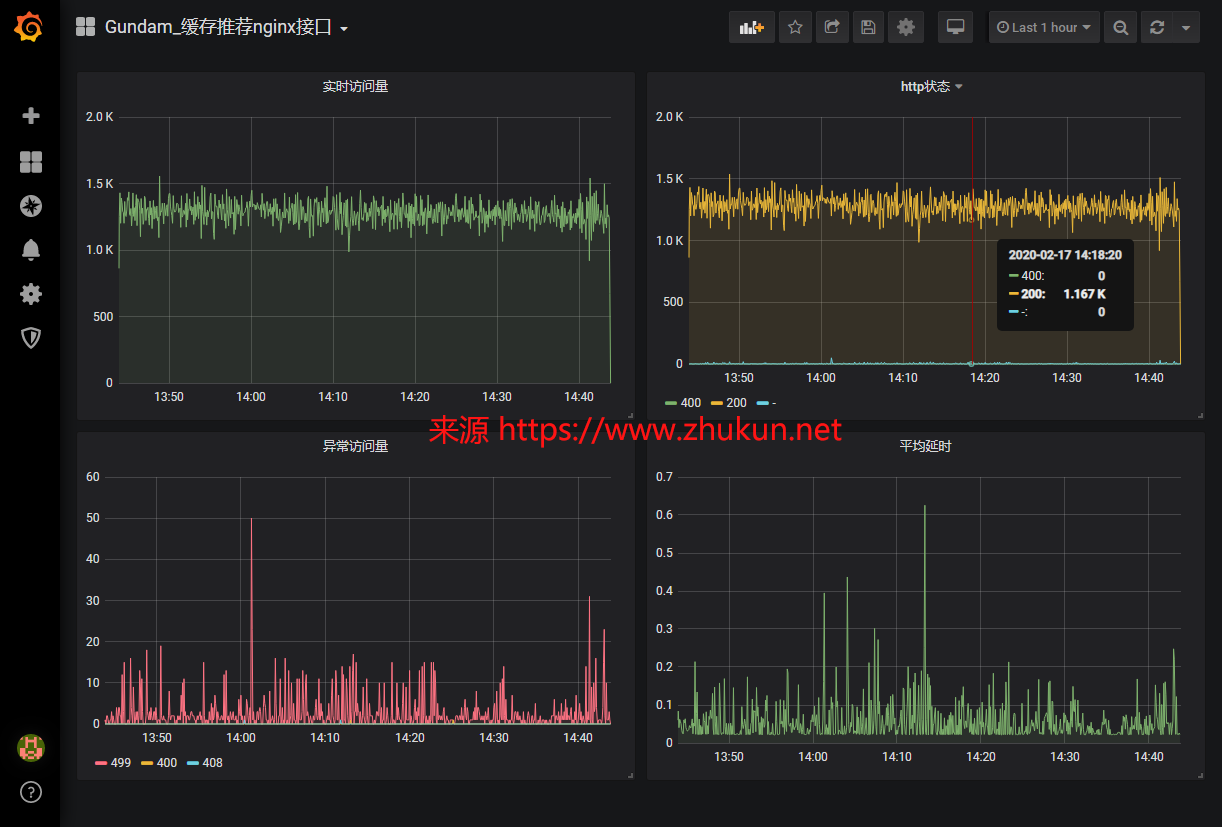
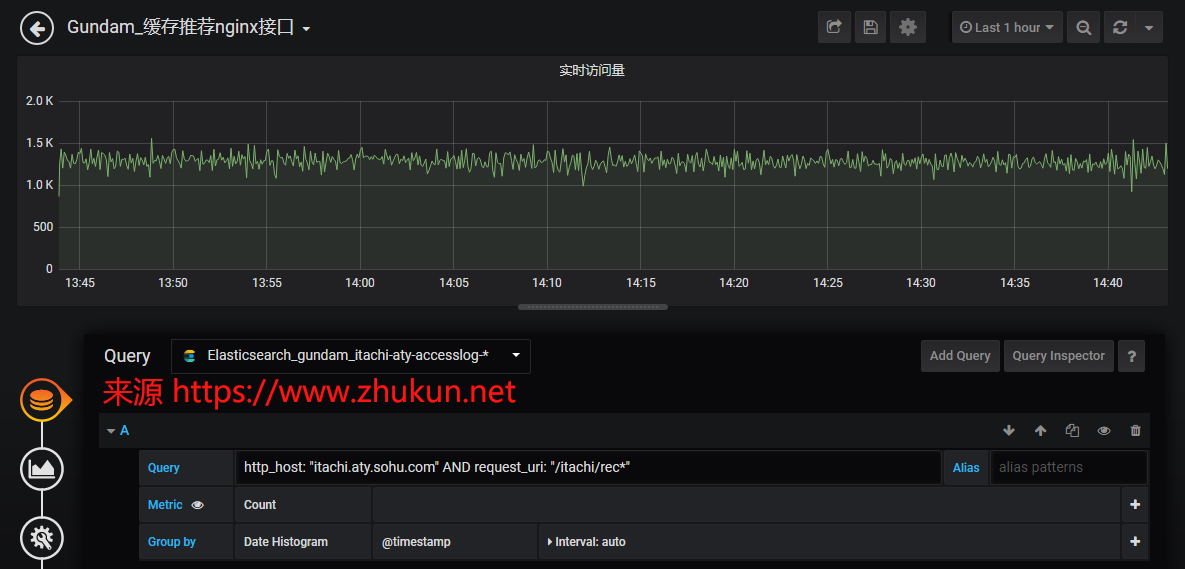
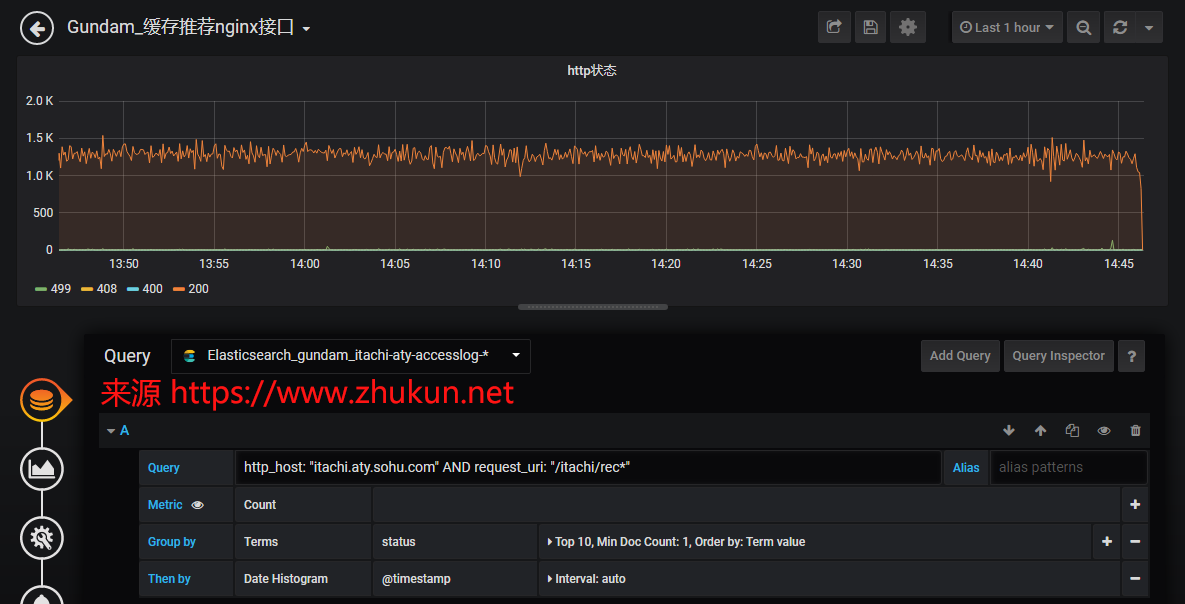
下面是每个metric的实际查询语法和简单设定:
小狼毫是一个跨平台的输入法, 以前在Windows上安装时, 添加五笔输入法的步骤总觉得很麻烦, 今天不小心看到个帖子, 才发现, 原来添加五笔模块是如此的简单, 这里记录一下.
1,从RIME网站下载并安装小狼毫输入法;
2,在开始程序中找到"【小狼毫】输入法设定";
3,点击"获取更多方案";
4,在弹出的命令行窗口中粘贴 https://github.com/rime/rime-wubi 然后回车
就是这么简单. 这样完成之后, 添加的小狼毫输入法仍是不能打五笔, 目测是需要重启一下电脑, 有谁知道不重启的办法, 麻烦留言告知一下.
Read MoreWindows平台下替代鲁大师查看电脑硬件配置信息的工具,目前推荐HWinfo64和Speecy,二者目前都是免费,且都可以通过Google搜索到。
简单试用了下,来说了二者的区别吧。
从某知名视频网站下载了一个小视频, 1080P 25帧的, 比特率是2600kbps, 格式为H.264/AVC, 视频长度为5分钟, 才98M的体积. 某天心血来潮想把它转换为H.265/HEVC格式的视频, 试了无数次才发现, 用现有的工具, 转换出来的H.265/HEVC格式的视频, 体积比它大的, 可能还没有它清晰, 体积比它小的, 清晰度就差更多了. 传说中的H.265/HEVC的优势哪里去了?
Constant Quantization Parameter, 恒定量化编码模式, 也称 CQ (constant quantizer)模式, 英文解释为The quantization parameter defines how much information to discard from a given block of pixels (a Macroblock), 此参数控制每个宏块(Macroblock)的压缩量. 此值越大, 表示要丢弃的Macroblock就越多(压缩率越大), 视频体积越小, 同时视频质量越差. 一般是用GPU转码时, 才会有CQP选项. 不建议使用此模式, 原因如下
Setting a fixed QP means that the resulting bitrate will be varying strongly depending on each scene’s complexity, and it will result in rather inefficient encodes for your input video. You may waste space and you have no control of the actual bitrate.
平均比特率, 这个不多说了. 不建议使用此模式. 老外的分析如下
Read MoreOne of the main x264 developers himself says you should never use it. Why? As the encoder doesn’t know exactly what’s ahead in time, it will have to guess how to reach that bitrate. This means that the rate itself will vary, especially at the beginning of the clip, and at some point reach the target. Especially for HAS-type streaming, this leads to huge quality variations within short segments.