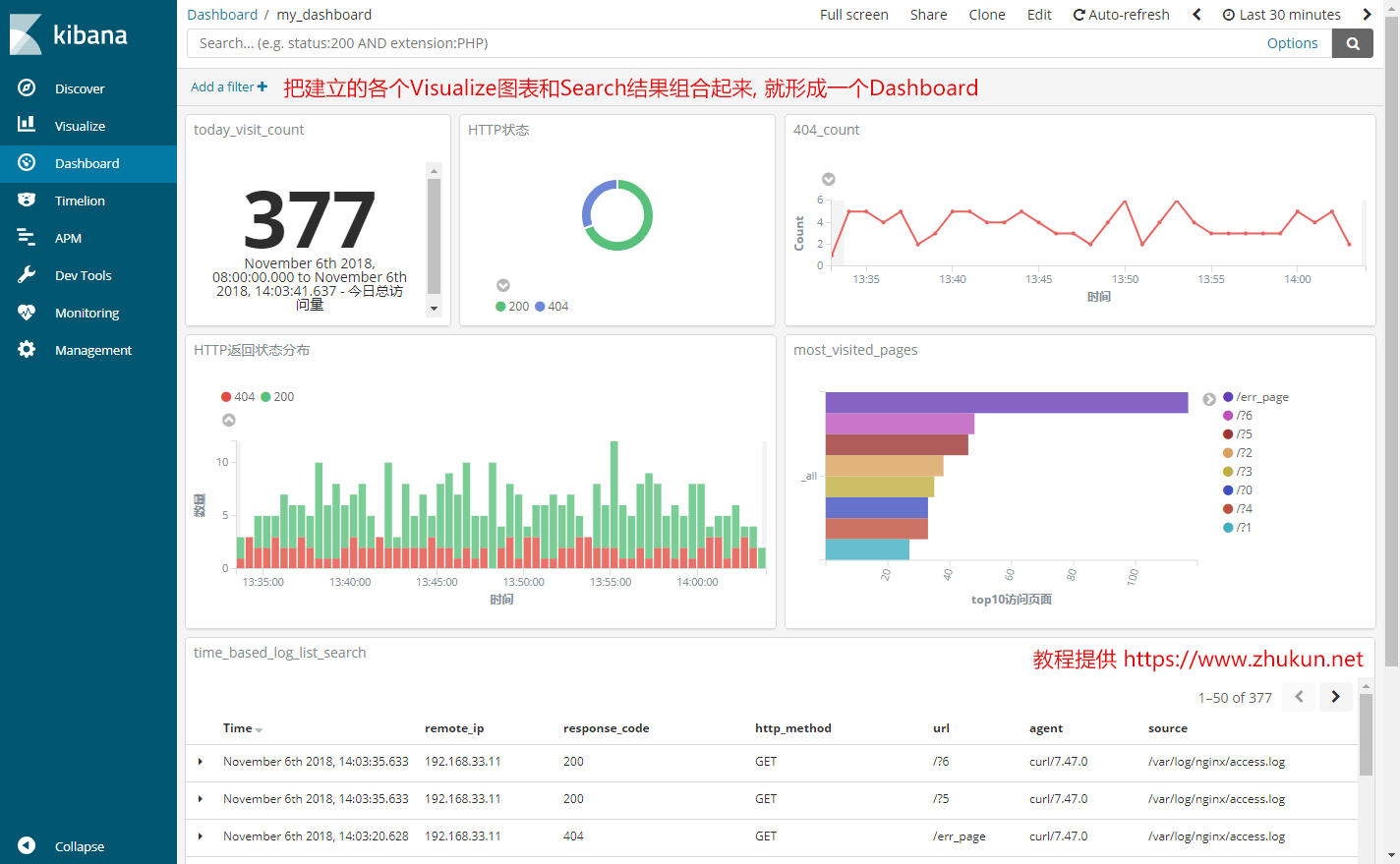
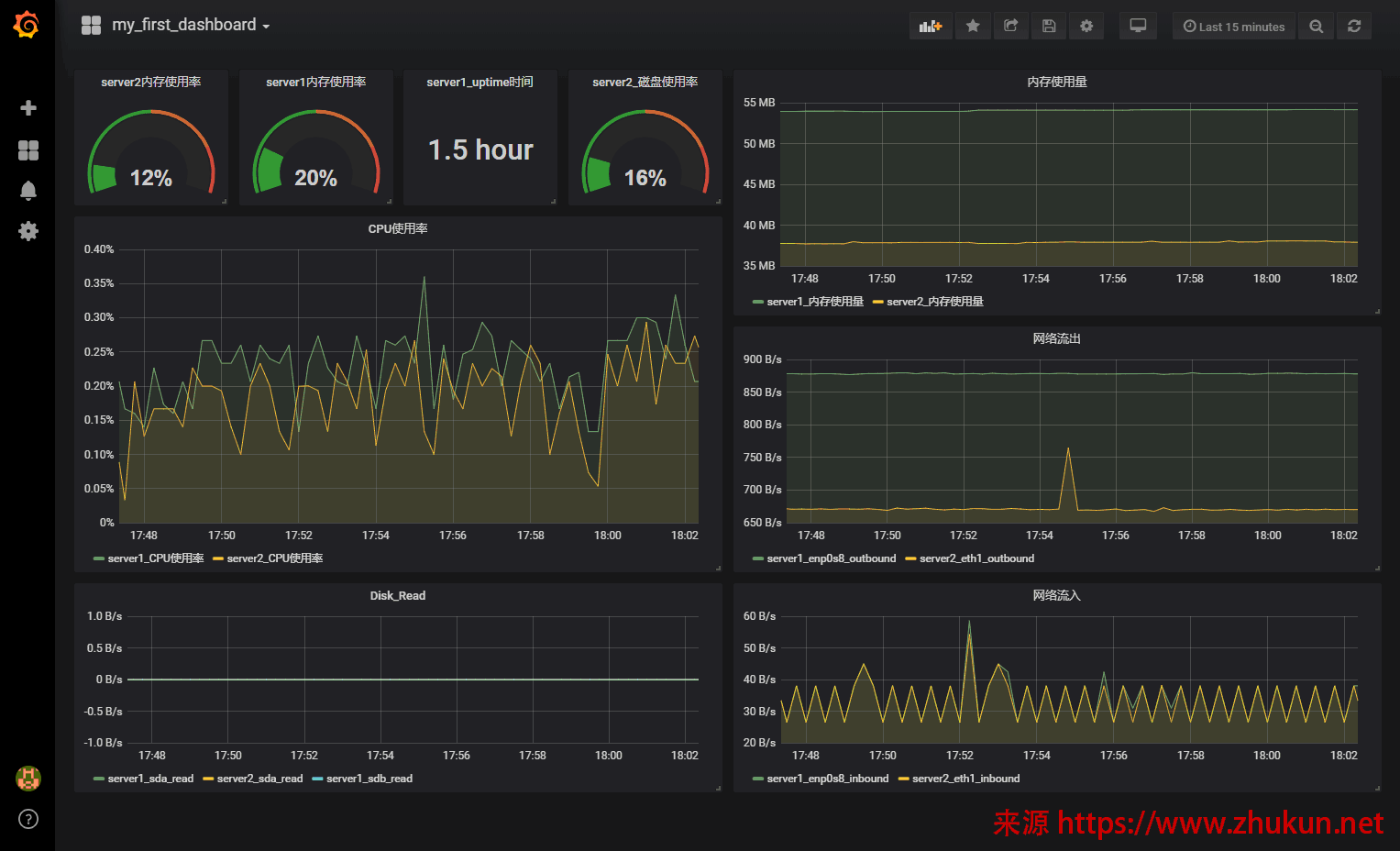
使用Collectd+Prometheus+Grafana监控nginx状态
在安装Nginx时,如果指定了–with-http_stub_status_module, 就可以使用本文的方法进行监控. 不用担心, 不论是从rpm/apt安装的Nginx, 均自带了该Module.
一般的建议是, 在nginx的机器上同时安装Collectd和collectd_exporter, 然后将数据导出到Prometheus(一般位于第三方服务器), 再从Grafana读取Prometheus中的数据.
1, 配置nginx
安装Nginx的过程此处略过, 我们需要确定一下Nginx安装了http_stub_status_module.
$ sudo nginx -V | grep http_sub_status
nginx version: nginx/1.14.0
built by gcc 4.8.5 20150623 (Red Hat 4.8.5-28) (GCC)
built with OpenSSL 1.0.2k-fips 26 Jan 2017
TLS SNI support enabled
configure arguments: --user=nginx --group=nginx --prefix=/usr/local/nginx --conf-path=...
配置Nginx启用该module
location /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
deny all;
}
然后便可以通过http://ip/nginx_status来获取相关状态信息.
$ curl http://127.0.0.1/nginx_status
Active connections: 29
server accepts handled requests
17750380 17750380 6225361
Reading: 0 Writing: 1 Waiting: 28